

PubMatic recently moved our data processing to Spark, as detailed by my colleague Satish Gopalani. This move lead to a number of learnings and resulted in key improvements which I will cover in more detail.
Key Challenges with Our Data Processing
Spark processing often leads to situations which are very hard to manage and it can create a number of problems if there are multiple jobs reading from multiple data sources. PubMatic was no exception and in our transition to moving our data processing to Spark, we had some important realizations that could benefit others.
The PubMatic team saw four key challenges:
- Too many jobs were consuming too many resources, thus creating a scarcity within the cluster
- Writing separate jobs to generate different views lead to repetitive code
- Business logic for individual dimensions and metrics within a report was often consistent and we needed to simplify to improve efficiency
- Writing new data processing jobs is costly and time-to-production is long with unit testing, QA automation and performance checks adding to the overhead
PubMatic’s Approach to Updating Our Framework
Organizations leveraging big data analytics must thoroughly understand the best practices first so they focus only on the most relevant data for analysis. The velocity, veracity, variety, and volume of data lying within organizations must be put to work to gain actionable insights. This can be a big challenge for any size company or engineering team. Additionally, understanding the business requirements and organizational goals is an equally important step to complete before leveraging big data analytics in your projects. In the long run, however, completing these steps will save a significant amount of time and effort.
Thus, prior to updating our big data processing framework, we took time to identify and analyze our business use cases. The following were established as the goals for the solution:
- Create a library of common business functions and re-use them across multiple jobs
- Most of the use cases were simple enough and used basic data processing constructs such as FILTER, JOIN, AGGREGATE. These become common APIs to be called upon as required.
- Provide a simple self-service framework to different product teams to develop data processing pipelines independently
- Encapsulate core big data APIs and provide intuitive interfaces
- Reuse code and datasets which would allow us to store intermediate results that can feed into multiple jobs, thus avoiding repetitive processing
Spark APIs and behavior suited our use cases and pattern of workflows. We simply had to encapsulate the solution in a way that solved our key challenges. We built a framework adhering to the above principles and came up with the below design:
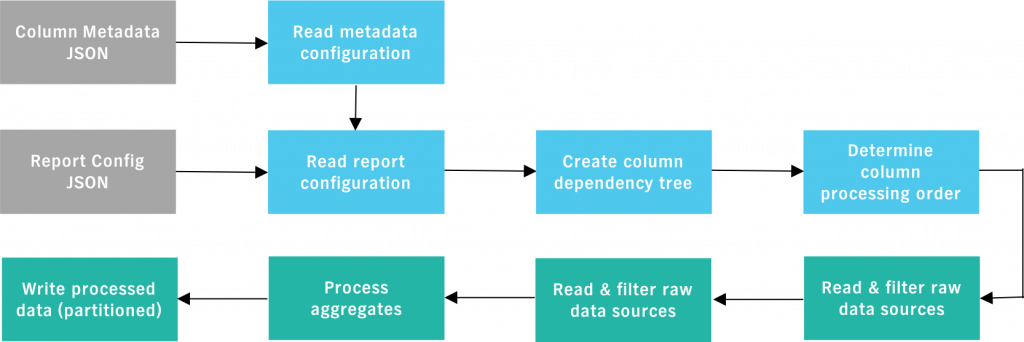
Key aspects of the design
- Build a dictionary of attributes and categorize them as raw, dependent, or derived
- Register columns along with their implementation:
- Business logic to derive a column value can be registered with the framework in the form of simple Java/Scala implementation of a standard interface
- Once registered, these implementation classes can be leveraged to generate reports across multiple data sources
- Build a hierarchy of jobs from a parent job to avoid repetitive jobs and processing
- Oozie helped us build job hierarchies which used intermediate results to feed into subsequent jobs
- Generate new reports/views using a configuration of the required columns in the report
Improvements in Moving to Spark
After our move, we noticed the following benefits:
- Development and QA timeframes were reduced for new jobs and reports
- Our migration of existing “Map Reduce” jobs to Spark was quicker with less challenges
- Improved speed on conducting POCs for new reports and columns to estimate resources required
- Improvement in resource utilization after moving all existing Map Reduce jobs to Spark
- Reduced lines of code in the repository helping us with more efficient maintenance
What’s Next?
We achieved significant flexibility by re-defining jobs and reports, reusing wherever possible. The next step is to build an ACTION-based mechanism to define the entire workflow in a configuration rather than coding it in driver classes.
To learn more about our recent updates, check out our engineering insights or if you would like to join our team, check out our open positions.
