

PubMatic receives more than 55 billion ad requests every day which results in processing more than 12 trillion advertiser bids each month. Processing this 50+ terabytes of compressed data (700+ terabytes of uncompressed data) daily is a huge challenge in itself.
Making the Shift from Hadoop to Spark
PubMatic started using Hadoop back in 2009 when Hadoop was in its infancy. We started with writing MapReduce, PIG and Hive queries but soon moved to our Cascading-based framework. It was a huge success because we could manage the complexities of writing MapReduce code using Cascading and focus more on our business logic and reporting.
When Spark offered distributed data processing, ease of programming and processing benefits, it became our next logical technologic move. We evaluated Spark in an internal Hackathon project in 2016 and found that using Spark and the Parquet file format together, we were able to reduce the processing time of our data by 40 percent.
Additionally, we could reduce the hardware load and dataset footprints by more than 50 percent from the current Avro format we were using. After seeing these results, we immediately prepared a plan to migrate our data processing platform from MapReduce to Spark.
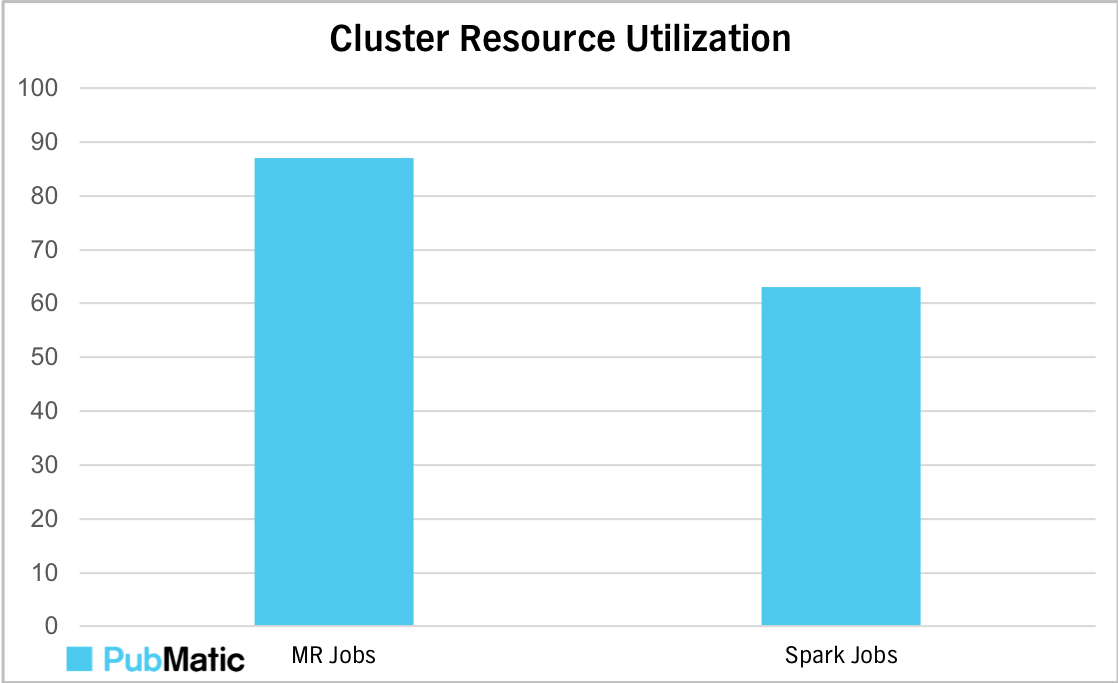
Graph shows the cluster resource utilization with new Spark jobs as compared to MR jobs.
Migration Learnings
Very early into the migration we realized that Spark was another challenge in-and-of-itself. Here are some of the key learnings and insights from our move to Spark:
- Parameter Tunings
- Compared to MapReduce, there is exponentially more tuning required for Spark, especially with large scale data like ours. While there are many recommendations out there, they may not be the best fit, so the only way to find the most optimal configurations is by performing multiple test iterations with various combinations.
- It is important to continually tune your configurations as some of the elements like data size, speed of data arrival, hardware, etc. change over time.
- Watch out because some of the parameter configurations are very specific to the environment (i.e. machine configuration or kernel versions). For instance, after a six month long constant struggle identifying the root cause for PARSING_ERROR in snappy decompression, our team found that the issue was specific to the kernel and JVM version. There was a hidden flag, “file.transferTo,” which disabled the NIO feature and thus solved our problem. (Spark Bug: SPARK-3948 & SPARK-20868 Code Ref: here)
- Stage Configurations
- MapReduce has only two stages: Map and Reduce. While this was a useful tool, it was limiting because you would have to fit everything into one of these phases. While Spark did a great job removing this limitation, it introduced new complications whereby the number of stages in your job are not easily visible and that results in a very complicated job.
We learned that in some instances, jobs would take much more time to complete as the initial stage required a lot of heavy lifting despite development being quick. Make sure to factor this in your planning.
- After much analysis and trial-and-error, we found that splitting the job into multiple, smaller jobs (i.e. writing to HDFS and reading back) resulted in better performance than a single, monolithic job.
- Spark Job Debugging
- While Spark does a great job in improving the ease of development, I think the debugging functionality needs more time to mature. For example, as in MapReduce, you can see the exact percentage of job that is complete at a particular time. However, you cannot kill a particular task which is running for a long time (a functionality supported in MapReduce).
- Getting logs for a running job can be difficult which can make debugging Spark jobs hard. We learned the best way to handle this was to try adding more debug statements and piecemeal the testing job to nail down the specific issues.
- We developed a tool to analyze logs from various running executors and get the exact error from a running job. This tool really helped us save a great amount of human effort into checking each executor log for errors. Having a similar resource would benefit others, too.
- Parquet, Avro, and CSV Support in Spark 1.6.x
- Spark natively supports the Parquet file format. If you are using Spark, or plan to, Parquet should be your defacto choice. Apart from being native to Spark, the Parquet format supports a high level of compression, compared to Avro. This is thanks to its dictionary-based encoding and its columnar representation of data which makes it the preferred file format if you are running analytical queries on a dataset.
- Support for Avro and the CSV file format in Spark 1.6 is present but not as mature. This made us either write data into Parquet or change some of the reporting items where a CSV was a need. For example, the CSV writer in Spark 1.6 does not support writing partitioned data (Spark 2.0 does support this) which is one of the crucial parts to us since it is a lifesaver while querying the dataset.
- Even writing partitioned data using Parquet creates directories with names such as “partition_column=<value>” which is not very helpful. We plugged in our additional handles to rename it with just the value, without the column name prefix.
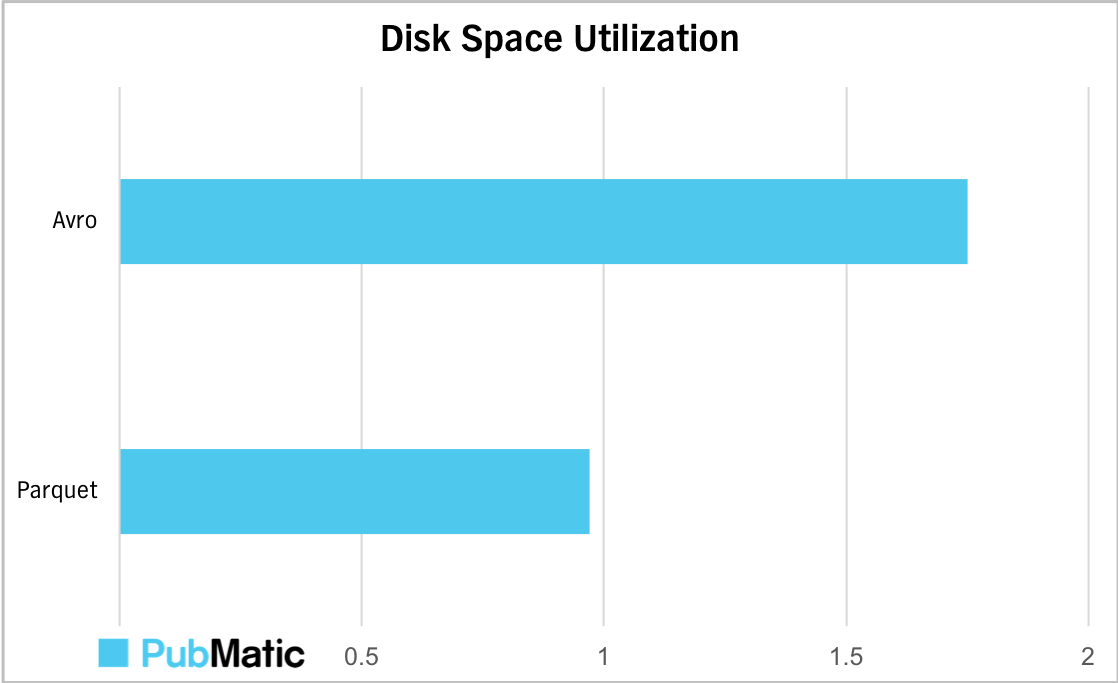
Graph shows the gains in disk space with parquet file format as compared to Avro file format for one hour worth of data.
Overall, it was a great experience moving to Spark and we learned a great deal in the process. It is hard to miss our increased data processing capacity by more than 40 percent with the move to Spark along with more than 50 percent saving in data footprint with Parquet. This allows us to be process more data, more efficiently, improving our ability to serve our clients with higher quality products.
What’s Next?
To learn more about what PubMatic is doing to improve our engineering processes and tools, check out our recent posts. If you are interested in joining our team and participating in our work, check out our open positions now.

