

Over the last few years, PubMatic’s data platform has scaled to processing hundreds of billions of events per day and the number of business processes that rely on data-driven decision-making has scaled as well. An incomplete picture of available data can lead to misleading reports, spurious analytic conclusions, and inhibited decision-making. At the same time our customers have an ever-increasing number of use cases that require real-time insights. These include understanding if a priority deal is getting transacted correctly, gauging the traffic patterns for a particular DSP/buyer, and determining if a new partner is onboarding well on our platform.
The ingestion module at PubMatic is primarily responsible for fetching all logs via Kafka from our ad servers at data centers across the globe. Our earlier data ingestion module was built in-house in 2014 and since that time we have upgraded and added multiple features. But the need for reliability at scale, and growing need for real-time data insights, made it imperative that we re-architect our ingestion module.
In 2020, we started a project to rewrite our ingestion module completely from scratch. We named it “IngX” as we wanted it to do more than just handle data ingestion. If you are building a data platform one of the most critical components is the data ingestion module. Get this wrong and you’ll find data delivery speed hit hard and data quality called into question. Writing a new ingestion module was a challenge and needed a lot of design decisions at every step. Let’s walk through some of the key design decisions we made while working on the new ingestion module.
- What framework should we choose to write our new ingestion module?
The first question was which tool or framework to use to build our new ingestion module. We evaluated several tools and frameworks, including Apache Gobblin, Kafka Connect, Apache Beam, Apache Flink, and Spark Streaming. Each tool had lot to offer but could not satisfy our stringent SLAs and high reliability standards. Our process for evaluating and shortlisting different tools could be a topic for another blog. We looked deeper at two options that came closer to our requirements: Apache Flink and Spark Streaming. Both these frameworks have good adoption, community and commercial support, and comparable performance. This made our decision even more difficult and complex. Finally, we introduced a scoring matrix, rated both frameworks, and chose Spark Streaming for its performance and maintainability. A key factor was also the reasonable learning curve for team members who have experience building batch applications in Apache Spark. - Spark Streaming or Spark Structured Streaming?
Spark has two flavors of streaming, and both differ in their APIs and in how they execute the workload. Spark Streaming works in a micro-batching fashion where it polls the source after every batch duration and then a batch is created of the received data — each incoming record belongs to a batch of DStream. In Spark Structured Streaming, there is no concept of a batch. The received data in a trigger is appended to the continuously flowing data stream. Each row of the data stream is processed, and the result is updated into the unbounded result table. Both flavors were similar in performance for our use case, however, with Structured Streaming we can easily apply any SQL query (using DataFrame API) or Scala operations (using Dataset API) on streaming data since it is built on Spark SQL library. While we began with Spark Streaming, we soon determined that Spark Structured Streaming was the future, as that is what the Spark community has shifted its focus to. - Where should we maintain data offsets?
Spark Structured Streaming manages offsets (that point at which the ingestion module has read data) into the checkpoint directory in HDFS (Hadoop distributed file system), but this introduces small file challenges. We chose to maintain offsets in Kafka itself, as it has multiple advantages including lag monitoring (how fast/slow it can pull data from Kafka) and saves us from small offset file issues on HDFS. Although Spark Structured Streaming regularly handles compaction of metadata files, it has its own challenges. Once compaction files grow large enough then the job spends a good amount of time in compaction, and this can impact performance. - Should we use FlatMap or MapPartitions?
This is one of the most frequent questions if you are transforming your datasets in Spark. FlatMap is a transformation which is applied to each element of RDD (Spark’s resilient distributed dataset) while MapPartitions are applied to each partition of the RDD. MapPartitions seems to a better option considering it provides opportunities to do efficient local aggregation and avoid repetitive cost of heavy initialization, but we found that for our dataset, FlatMap was more effective. In our use case, we saw almost 25% better performance with FlatMap, extracting multiple records from a single GZip compressed record from Kafka and converting it to Avro Deserialized Spark Row.
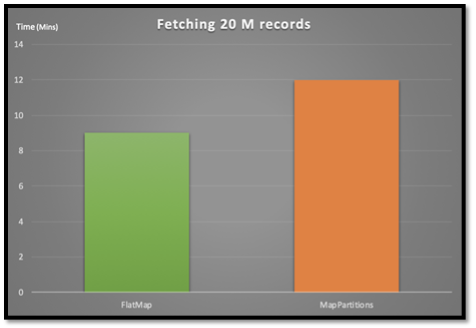 Illustration above shows a comparison between FlatMap and MapPartitions for fetching 20 million records (lower is better).
Illustration above shows a comparison between FlatMap and MapPartitions for fetching 20 million records (lower is better).
- How should we shut down Ingestion module gracefully?
Streaming jobs are long-running jobs, but there are cases when we want to gracefully shut down the job –for redeployment or to update a Spark configuration. A graceful shutdown means ensuring that Spark jobs shut down in a recoverable state and without any data loss or duplication. Spark does not provide a way to gracefully shut down a running streaming job, so we had to develop our own method. We used a Poison Pill design pattern, in which our application monitors for a marker file on HDFS and if it is not present, then it will stop the streaming job after finishing the current stream of data that it has fetched from Kafka. This ensures that jobs shut down gracefully in a recoverable state and without any data loss or duplication.
The following are some of the benefits of the new IngX pipeline:
- Performance
We can process 1.5 to 2x more data with the same number of resources while making data available much earlier. - Real Time Support
The IngX pipeline has enabled us to build our real-time analytics pipeline, which allows our end users to get insights into data as it flows. - Better Offset Management
Offset management is a lot simpler and gives us granular control to resume jobs from a particular offset or a particular hour. This is useful in handling issues and maintenance activities. - Better Monitoring
With Grafana-based monitoring, ingestion module lag monitoring, data flow patterns, load analysis, valid and corrupt record analysis all has been centralized and available in a graphical format for visualization. - Single Framework
With IngX, we are moving toward Kappa Architecture, which has enabled us to build our streaming and batch processing systems on a single technology. There are a high number of Dev-QA cycles saved through reusing the same business logic in both pipelines.
Building a new ingestion module was not an easy task and it involved a lot of crucial decision-making at each step. This article highlighted just some of the important steps. This project has opened a lot of avenues to support new use cases – such as debugging real-time streaming data – that were not even possible earlier.

