

PubMatic’s scale increased from processing fewer than 90 billion ad impressions per day to almost 134 billion ad impressions per day in a span of less than a year. Our data capacity also more than doubled (72 TB per day to > 150 TB per day) during this period.
| December 2019 | October 2020 | |
|---|---|---|
| Ad Impressions Per day | 80 billion | 134 billion |
| Raw data size Per day | 72 TB | 150 TB |
| Overall data size | 15 PB | 30 PB |
| Customers | About 1000 | More than 1700 |
In late 2018, we moved almost all of our data processing to Spark-based frameworks, as described in these articles: https://pubmatic.com/blog/data-processing-framework/ and https://pubmatic.com/blog/engineering-learnings-spark/.
Challenges:
An increase in volume and data can bring scale and performance challenges.
- While initially the Spark jobs were linearly scaling with volume, a steep lag was observed over a period of time. On digging deeper, we realized that the cardinalities of some of the attributes increased exponentially.
- The major culprit was an attribute of array data types. When the ad impression volume was around 100 billion, the average length of that array attribute was 2.5 – 3 elements per record. When we reached a volume of 120 billion, the average length of the array attribute increased to 9 – 10 elements per record.
- The Spark jobs extract individual elements from the array attribute and aggregates those elements.
- The exponential increase in the array length degraded Spark job performance. It also led to increased latencies for all downstream jobs.
- The number of Spark jobs increased significantly with growing scale. While making room for new Spark jobs we set about optimizing them.
- We observed that some jobs do not require a lot of memory, such as those that were IO intensive. So simply providing more memory would not have helped. In this case the challenge was a high number of tasks which ranged in tens of thousands. Spawning thousands of tasks is not optimal specially if the individual task completion time is less than the time it takes to spawn and set up a new task.
- There was previously significant processing time invested in reading and writing the intermediate results from long chained applications.
Optimizations
Data Structure optimizations:
- We observed that individual elements within the array attribute were not consumed until very late in the processing pipeline.
- Additionally, the values in that attribute were getting aggregated with functionally incompatible attributes. This was resulting in significantly high shuffle data and degraded performance.
- As an example, for an input record containing attributes D1,D2,D3,D4,<D11,D12,D13> , the aggregated result was:
- D1,D2,D3,D4,0,1,1
- D1,D2,D3,D4,D11,1,0
- D1,D2,D3,D4,D12,1,0
- D1,D2,D3,D4,D13,1,0
- As an example, for an input record containing attributes D1,D2,D3,D4,<D11,D12,D13> , the aggregated result was:
This was changed to :
- D1,D2,D3,1 D1,D11,1
- D1,D12,1
- D1,D13,1
- The first optimization delayed array explosion i.e. extracting elements from the array until further in the processing pipeline, and separating it from the incompatible attributes.
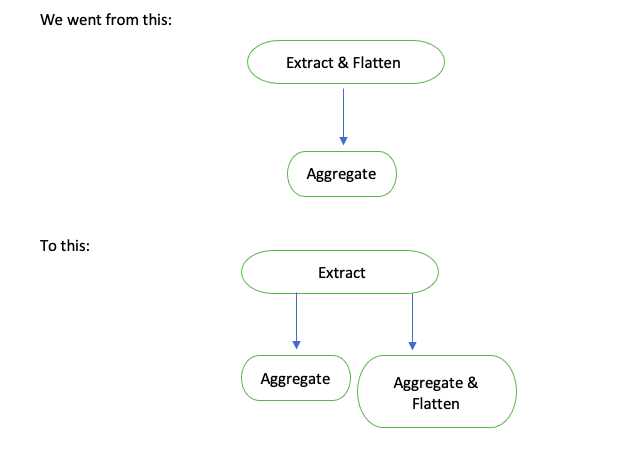
Results
- The Extract application resulted in a more than 30% performance improvement. In addition, we reduced the output data size by 25%.
- The aggregate functions also improved ~25% as they had less processing to handle.
- This helped us to better prioritize our datasets into key metrics and troubleshooting metrics.
Memory vs Parallelism:
- One of Spark’s selling points is that it takes 10x-100x less time to finish a similar job written as Hadoop Map-Reduce. The trick is to store data reliably in-memory – this makes repeatedly accessing it (ie. for iterative algorithms) incomparably faster.
- However, Spark simply cannot keep getting better if you continuously keep increasing memory.
- Underneath Spark lies Hadoop and HDFS (Hadoop Distributed File System) which has block as the smallest unit of processing. So even if your Spark executors have GBs of memory per task, it will only utilize the memory requirements to process a block’s worth of data, typically 128 MB to 256 MB.
- We experimented with an interesting Spark property: sql.files.maxPartitionBytes
- This basically combines your small partitions/blocks into one big block of the specified size.
- We observed that for some of our IO-intensive jobs, increasing the property beyond 256 MB helped improve overall job performance.
- It might seem contradictory to have relatively smaller blocks (not too small, of course) so that they can be parallelly processed. But having too many tasks and executors leads to additional time required in launching and terminating tasks which adds to the overall job processing time. This works well for Spark applications running on clusters that have ample memory.
- Obviously, you have to find the sweet spot based on your applications and use cases. Our applications ranged from 128 MB to 512 MB block sizes. You need to increase the memory per executor if you are increasing the block size and decrease it if the block size is dropped.
Apache Ignite:
- Spark has a robust caching mechanism that can be used for job chaining and applications that need to have intermediate results. But we have not reaped benefits form our experience using Dataframe cache, especially if the intermediate results are several hundred GB in size. As well, Spark does not support sharing of Datasets across different applications.
- Thus we had to follow the traditional approach of writing intermediate results onto HDFS and having them read back again by downstream jobs.
- We then evaluated Apache Ignite – an in-memory computing database.
- Apache Ignite is an open source in-memory data fabric that provides a wide variety of computing solutions, including an in-memory data grid, compute grid, streaming, as well as acceleration solutions for Hadoop and Spark.
- Ignite provides an implementation of the Spark RDD, called Ignite RDD. This implementation allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory across different Spark jobs, workers, or applications.
- The idea is to have Apache Ignite running on every server. It consumes roughly 20% of the server’s memory and act as an in-memory cache for Spark datasets. The Spark applications write data onto the Ignite layer instead of HDFS, and subsequent applications then simply read from the cached Ignite layer.
Results:
- Using Apache Ignite, we were able to improve the performance of some of our Spark applications by up to 15%.
- However, the parent application writing into Ignite degraded by an order of 15-20%.
Pros:
- Ignite maintains copies of data across nodes so that the overall HDFS reliability aspect is maintained.
- Reading from Ignite is significantly faster than reading from HDFS.
- Very little to no code changes are required to make your existing applications read and write from HDFS.
Cons:
- Writing onto the Ignite cache layer is slower than HDFS as Ignite creates indexes for faster reads.
- Currently complex datatypes like arrays are not supported. Since Apache Ignite is practically a database, data needs to have a primary key.
Next Steps:
- Optimization is a continuous process and one has to constantly identity the right enhancements to ensure applications are performing within expected SLAs.
- PubMatic is continuously scaling its platform, and at the same time we are optimizing our infrastructure through cutting edge technologies and tools.
- We will continue to explore Apache Ignite further to see how we can make it more useful for our data processing pipelines.
Key Takeaways
- With the rise in scale and volume, it is key to find the right balance between compute and memory optimizations. Simply scaling either of them will not always work.
- One need not change complete algorithms or technologies to get good optimizations. Simply adopting to the right data structures can solve many problems.
- There are plenty of tools and technologies on the market. We not only need to identify the right ones but also need to tune it to our needs and the needs of our customers.
