

Adtech is an industry built on solving complex problems. As the ecosystem scales – and as PubMatic scales its global infrastructure and capabilities – we’ve looked at optimizing MySQL to handle the complexity of the very large datasets inherent to the business and successful implementation on behalf of our customers. While new and flashy strategies can grab attention, production-hardened technologies that simply just work are ideal. Years of bug-fixes and stability improvements have gone into making MySQL fit this bill.
Some may say that MySQL may not be the right tool for handling large datasets, something that No-SQL technologies do more effectively. The scale of data is definitely not the only criteria for assessment and the key is to know when to use which in a given situation.
MySQL has advantages that include:
- MySQL is fully ACID (atomicity, consistency, isolation, and durability) compliant.
- An extremely mature and well-known query language.
- Being well-suited for complex queries.
- Good suitability for transaction-oriented systems.
- MySQL 8 provides document store features.
PubMatic’s Ad Quality team uses MySQL as its main data source. Some of our tables have up to a couple of hundred million records and their size ranges from tens to hundreds of gigabytes. Millions of creatives are scanned daily, with APIs/scheduled jobs crunching, processing, and storing data around the clock. Benchmarking is important to measure how our applications behave under certain loads. So, we capture and maintain numbers for 2x-10x loads. These are used for each incremental iteration and regression. There are some strategies which have helped us scale our throughput and reduce processing time despite working with large tables and data. They can be classified as:
- Read optimizations
- Write optimizations
- Administration/setup optimizations
- Design optimizations
Read optimizations
Indexes are data structures that help MySQL retrieve data efficiently. They play a key role in ensuring good query performance. A good practice we have followed is to analyze indexes for all tables, starting with high volume insert/read tables.
We can subtly rewrite queries so that they use the lesser-considered covering indexes, indexes that contain all the data needed to satisfy a query. As the indexes’ leaf nodes contain the row data, we can use covering indexes to get the data we want from the index itself without reading the actual row. They can be a very powerful tool to dramatically improve performance. Index entries are usually much smaller than the full row size, so MySQL can access significantly less data if it only reads the index.
Oftentimes we land in a situation where we need to index a rather long string column. For such use cases we have simulated a hash index by creating another column with crc32/md5 of the large column and have indexed that column. This works well because the MySQL query optimizer notices there’s a small, highly selective index on the crc32/md5 column and does an index lookup for entries with that value. Make sure you handle collisions by including the literal value in the where clause.
The explain command is your best friend
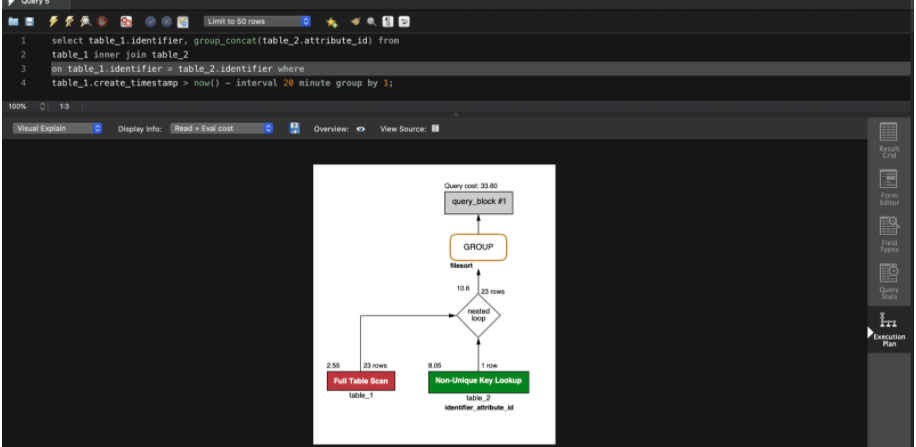
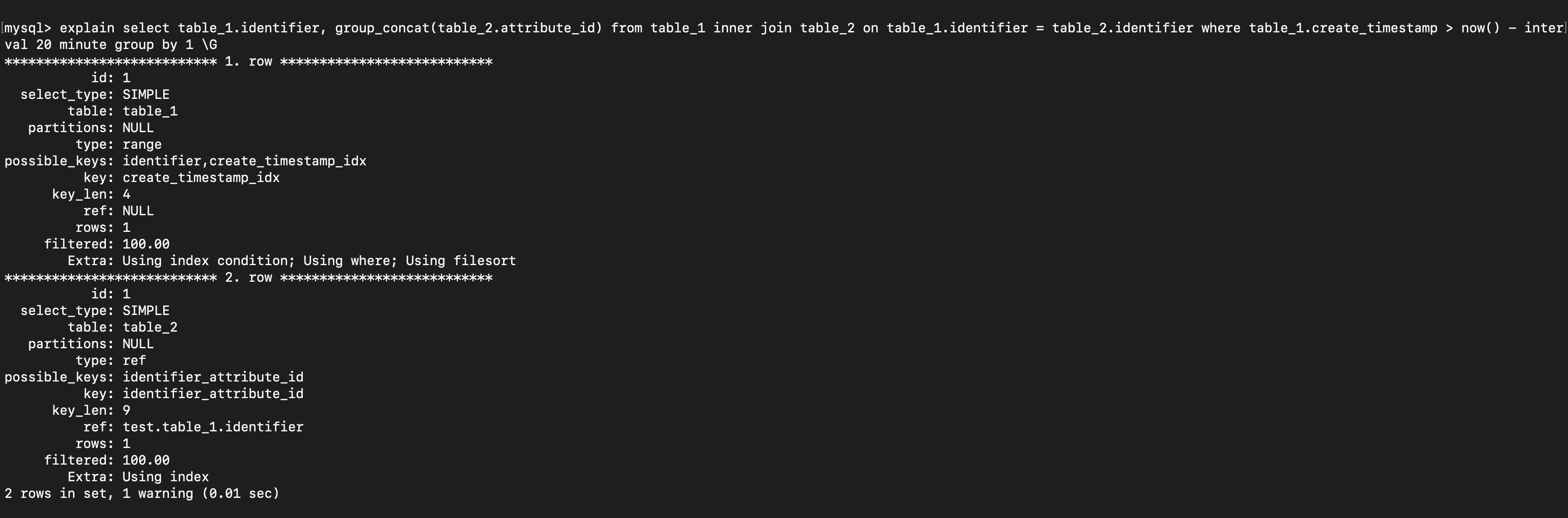
The explain command helps us understand each step in the query execution plan. A practice which we thoroughly follow is to review the explain output of every query before it goes to production, especially ones which execute on large tables. You can use the MySQL Workbench visual/tabular explain tool to view the query execution plan. Review the key (shows which index the optimizer decided to use to minimize query cost), possible_keys ,extra columns in the output.
Offload your heavy queries to read-only replica servers
As we scaled one of our applications across data centers, we faced performance challenges related to reading from the primary source node. To solve this, we added replica read-only servers in each data center and offloaded read queries to them. We also run time-consuming read queries from these read-only servers for some of our reporting needs.
Write optimizations
Optimize inserts using batch processing wherever possible. By doing this we saw a 50%-to-80% time improvement for several jobs.
If you are using JDBC, you can achieve this using the rewriteBatchedStatements = true property.
Query generated with rewriteBatchedStatements = true

Query generated with rewriteBatchedStatements = false

Setting rewriteBatchedStatements to true hints the JDBC to pack as many queries as possible into a single network packet, lowering the network overhead. MySQL Connector/J internally analyzes the max_allowed_packet variable and creates batches accordingly. You can still use this technique (via code) even if your driver/connector does not support this rewriting feature. Just make sure that the batches do not exceed the max_allowed_packet size.
Use the IN clause effectively
To optimize delete/update queries we can batch data using the IN clause.

Make sure to limit number of entries in the IN clause. If the number is large the MySQL optimizer may choose to not use an index. Enable the MySQL general log during development and analysis to check whether batching is working as desired.
Get rid of unnecessary indexes
Remove any unnecessary indexes from the tables. More indexes mean slower inserts; more indexes mean more disk and memory space occupied. We can identify unused table indexes from the performance schema and then use Percona’s pt-online-schema-change to remove these.
Administration/setup optimizations
Data life cycle management
Active pruning
It is important to consider and plan for growth in data at the outset. Do not consider pruning as an afterthought.
Pruning strategies
- Evaluate table data and figure out which table requires how much data.
- Percona’s pt-archiver tool can yield very good results.
- Delete using primary key wherever possible.
Backup and recovery
We regularly back-up our databases to cloud storage. As the product evolves, we may need to add/modify columns, etc. to production tables. However, as the alter command locks writes on the table so we must avoid running alter on large tables. It is important to think through the data migration strategy. Consider using Percona’s pt-online-schema-change. Perform thorough tests before using this on production.
The devil is in the details
The default configuration with which MySQL ships with may not be ideal to support data intensive applications. These were some of the properties we tuned and have helped us gain performance.
innodb_buffer_pool_size
innodb_log_file_size
innodb_write_io_threads
innodb_read_io_threads
table_open_cache
table_definition_cache
tmp_table_size
max_heap_table_size
read_buffer_size
read_rnd_buffer_size
join_buffer_size
sort_buffer_size
Validating these property changes can be tricky. As mentioned earlier our benchmarking process has helped us understand the improvement/deterioration caused by changes we made. One can only optimize queries when we actually know they are slow. The slow query log is a great feature which MySQL provides to detect queries which have exceeded a predefined time limit. The key is to configure the correct threshold depending on the business use cases. We have setup automated workflows which notify us of the slow queries at regular intervals. Check availability of newer versions. They usually come with performance/stability fixes. It is important to triage open bugs and check if they will affect our applications before migrating to the newer version.
Design optimizations
The storage engine
We use the InnoDB storage engine. InnoDB uses row level locks whereas ISAM uses table-level locking. Transactions, foreign keys, and relationship constraints are not supported in MyISAM.
Data type design
Choosing the correct type to store your data is crucial to getting good performance. Operations on smaller data types are much faster as they use less space on the disk and in memory. They also generally require fewer CPU cycles to process. For example, use a varchar (64) compared to a varchar (200) if you know that the column size won’t increase beyond 64 characters. Be sure to estimate the column sizes correctly as later alteration could prove costly. It is recommended that you specify columns as NOT NULL unless you intend to store NULL in them. A nullable column uses more storage space and requires special processing inside MySQL. The timestamp contains time-zone information and requires only half the storage space compared to DATETIME. Note that it’s limit of storing time up to the year 2038 is much smaller than that of DATETIME.
Don’t normalize for the sake of it
We were always taught to try to normalize tables as best as possible to reduce redundancy. Denormalization is a database optimization technique in which we add redundant data to one or more tables. It is mainly used to speed up queries which would otherwise require joins across several tables (some tables could be very large which will make the joins very slow) to get the data we frequently need. Remember to evaluate your use cases as updates and inserts will be more expensive due to redundant data. Applications now have to ensure that there are no data anomalies as data can be changed at multiple places. Also consider avoiding cascade queries on large tables as these will block other queries.
For example, consider a case of having two tables:

consider we have an index on create_timestamp
Assume that the number of video creatives is much lesser than other creatives.
The query to get the latest 100 classified video creatives will look like:
select cd.creative_id, cd.creative_classification from creative c inner join creative_data cd on c.creative_id = cd.creative_id and c.creative_type = ‘video’ order by cd.create_timestamp desc limit 100;
To execute efficiently, MySQL will need to scan the create_timestamp index on the creative_data table. For each row it finds, it will need to check into the creative table and check whether the creative_type is video. This is inefficient because very less creatives have type video.
We can denormalize the data by adding column creative_type to the creative_data table and adding an index on (creative_type, create_timestamp). We can now write the query without a join.

select creative_id, creative_classification from creative_data where creative_type = ‘video’ order by create_timestamp desc limit 100;
As every application is different and has its nuances, I would say that there is no one-size-fits-all solution to improve the system. These were a few things which have worked well for us. I encourage you to try for yourself, and keep your MySQL database running efficiently and effectively when data and scale increases.
NOTE:
This article references specific examples and use cases that should not be taken as an endorsement or recommendation. Readers should use their own judgment to identify technologies that best meet their needs.