

One day last September, I was using ChatGPT to optimize my car insurance premium. Not only did I successfully reduce the premium from $190 to $140, it also inspired a light bulb moment; if I could do this for my car insurance, why not forSpark jobs at PubMatic? It was a simple realization but worth a shot – this was a problem looking for a solution, rather than the other way around.
PubMatic manages a massive data platform, handling about 1.9 trillion advertiser bids daily, running over 600 Spark jobs to process more than 16 petabytes of data. At this scale, every small optimization in our Spark pipeline directly reduces the cost and increases throughput in a significant way.
As a company focused on delivering both innovation and efficiency, we are always looking for ways to optimize the performance of our infrastructure.
Introducing Sparkle AI Agent
Our infrastructure is optimized to get the best out of investments but had previously required manual intervention according to varying workloads. The manual optimization processes in place were reactive – requiring human resources and time to react. This set the scene to experiment by combining the collected Spark job data on our observability platform with the expertise derived by PubMatic’s LLM (Large Language Model).
How It Started
We initially took a hands-on approach, manually uploading job parameters into anExcel sheet and prompting ChatGPT to optimize for either cost or speed based on job SLAs (Service Level Agreements). After refining our prompts, we applied AI-generated recommendations manually and saw immediate performance gains and cost savings, validating our initial gut feeling.
Scaling Up
The obvious next step? Automate it. We expanded our initiative by:
- Generating optimization recommendations across all existing jobs.
- Collaborating with the SRE (Site Reliability Engineering) team to apply high-impact changes in production.
- Iterating based on SRE feedback to improve our prompts and categorize optimizations.
Evolving the Process
Initially, our recommendations lacked quantifiable impact in dollars and speed improvements. Over time, we fine-tuned the system to:
- Accurately prioritize cost vs. speed trade-offs.
- Capture previously ignored inefficiencies(for example, unnecessary retries).
- Incorporate historical run-time data to predict savings before execution.
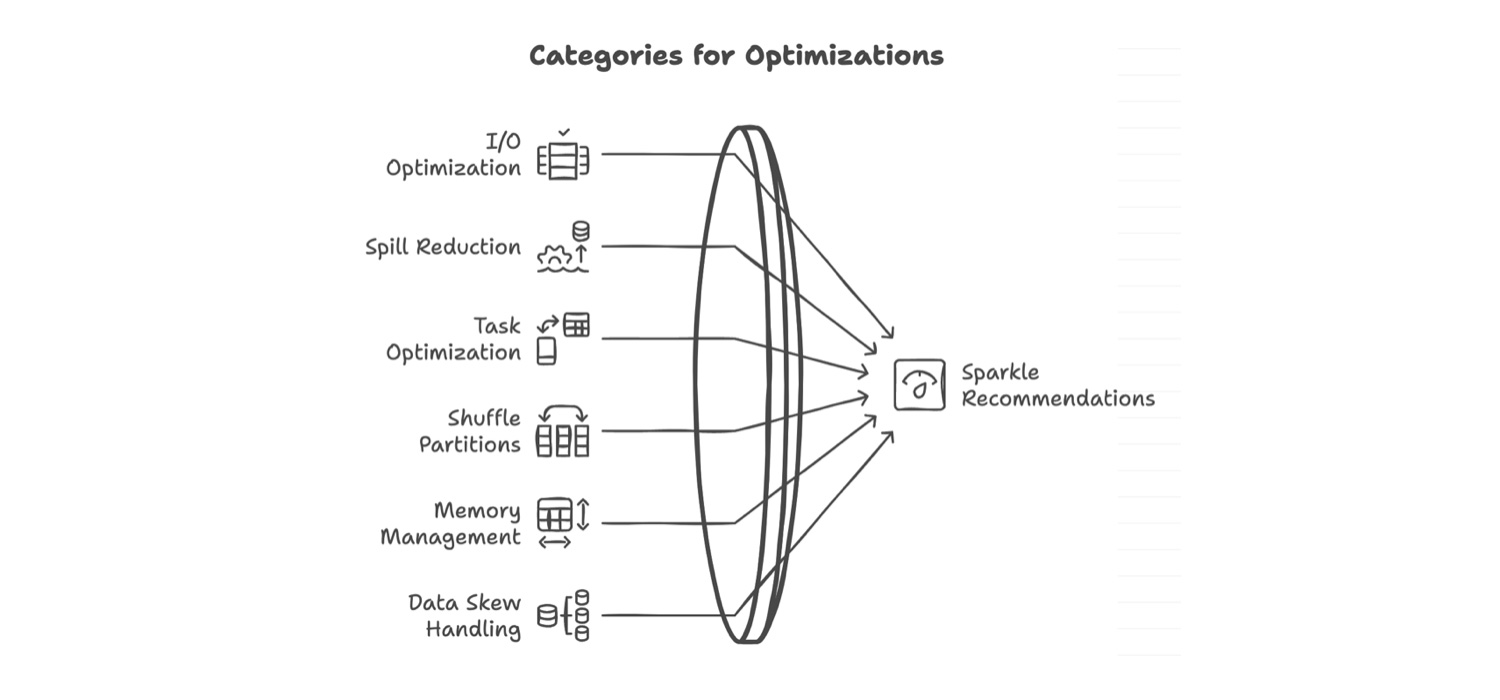
Further Refinements: Optimization Categories
As we learned, we further refined the process by bringing in six categories of optimization recommendation to better isolate and prioritize job recommendations.
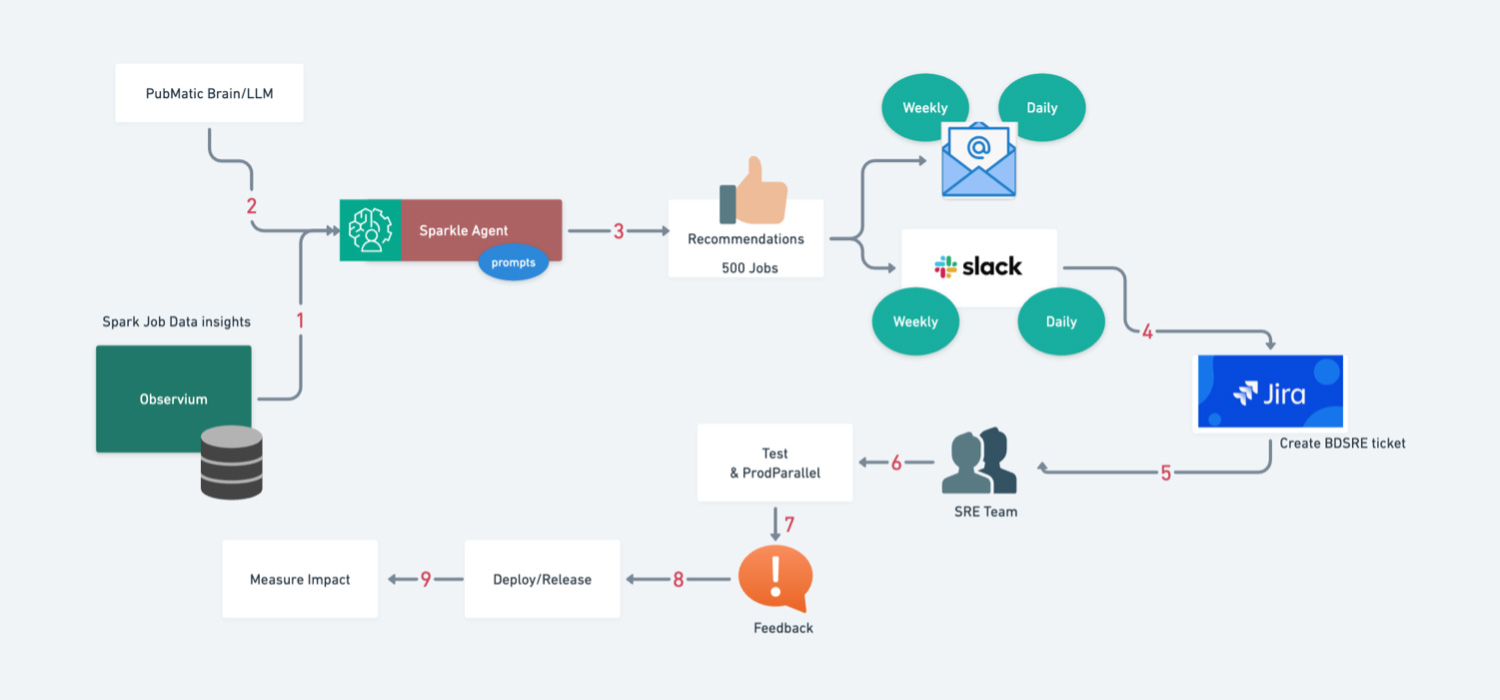
Here is an example of one optimization recommendation that we made live:

High-Level Block Diagram
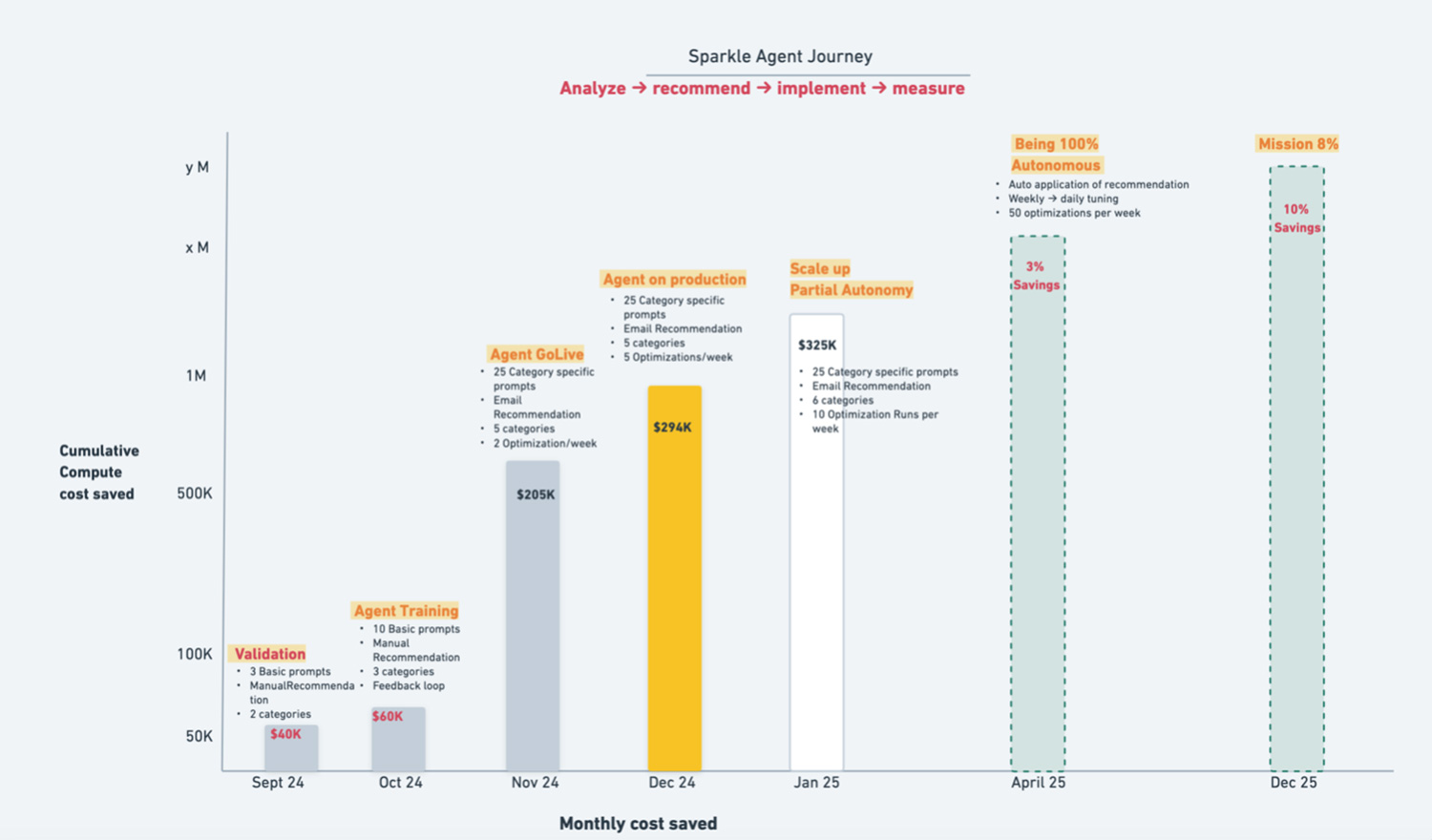
Results So Far
- The first 20 Spark jobs we optimized saved approximately $1M
- We expect to save approximately 3% worth of compute time by the end of May 2025
- We are on track to hit 10% compute time savings in 2025
These numbers aren’t projections – they’re real, tangible savings that keep compounding as we scale the optimization system.
Key Takeaways
- AI-assisted tuning scales where manual tuning fails. With the scale of the data we process daily, humans can’t tweak 600+ jobs effectively, but AI can.
- Cost savings compound at scale. Even small efficiency gains per job lead to millions in savings annually.
- Human + AI synergy matters. SRE feedback helped refine AI prompts, improving both automation and trust in recommendations.
What’s Next?
- Open-Sourcing the project– at PubMatic, we believe in giving back to the tech community. We’re making this framework available for public use.
- Autonomous Execution– we plan to remove manual clearance for non-critical jobs, making AI-driven optimizations truly autonomous.
If you are also looking to reduce overhead costs and improve Spark performance, get in touch with us.
By continuously looking for ways we can leverage AI to improve the efficiency of our platform, we can deliver better outcomes for our customers.

