

It is generally accepted that many users typically abandon websites and applications that take longer than three seconds to load. Therefore, quick response times are critical to keeping your users happy and engaged. PubMatic upholds high quality Application Programming Interface (API) performance standards and works to make sure load times and user experiences are optimal.
Our approach applies across all aspects of development: software and hardware architecture, data modelling, writing optimized code, and testing. However, there are uncertainties with processing billions of ads and petabytes of data. In addition, our infrastructure operates globally, runs on thousands of servers, and utilizes hundreds of software components. All of these varying factors can lead to unanticipated application performance issues.
Updating Our API Monitoring
Thus, to improve our API performance, we needed a lag monitoring and notification system to deliver product owners with comprehensive and detailed data.
The key requirements were:
- Monitor API response times
- Alert downstream integrations (e.g. Slack, Email and JIRA)
- Compatible with our existing Elasticsearch, Logstash, Kibana (ELK)-based log infrastructure
- Have a rule-based anomaly detection
After a careful evaluation of various open source and paid solutions, we selected an open source vendor named ElastAlert who is a cost-effective partner offering a seamless integration with our ELK-based infrastructure.
Set-up details:
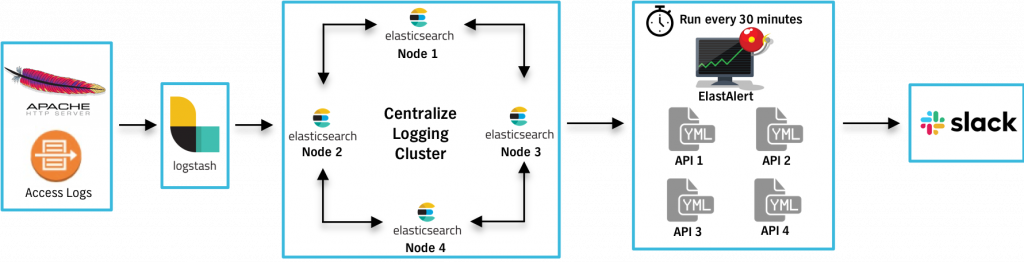
ElastAlert works on YML based rules. Typically, you define a separate YML file for each application and the rules are evaluated depending on the frequency specified in the file.
There are 3 key features:
- Loop-Back Window – A sliding-time window for when the logs should be collected and monitored; the system collects and evaluates the logs for the window.
- Request Pattern – Defined patterns for the API requests which acts as a filter and only matched requests are processed against the rules.
- Threshold Error Percentage – A pre-determined acceptable number of breaches per 100 requests (e.g., limit alerts to when breaches total more than 10 per 100 requests).
Monitoring Alerts
We also have downstream integrations with various communication tools such as Slack, email and JIRA. Every alert contains important details such as API name, percentage of violating requests, and a link to the Kibana Dashboard to facilitate further investigation.
The most common reasons for Service Level Agreement (SLA) breaches are:
- Nested APIs
Due to the explosion of micro-services in the market, many API calls are nested. Therefore, any downstream APIs data lag impacts the performance of the caller API. Setting timeouts and tuning the downstream APIs are common tactics to alleviate this issue. - Bulk Operation API
These require the system to perform thousands, or millions, of operations in a single request. Some techniques to manage this issue include query optimization, data compression, splitting, and parallel processing, thus increasing the SLA (as you cannot optimize this beyond a certain point). - Massive Response
This is a common use case where an API returns an enormous amount of data. Pagination, SQL tuning, caching, lazy loading, and reducing the number of fields are all remedies for huge response SLA breaches.
What’s Next?
While our ElastAlert-based system solution recently went live, we are continually improving our API performance – providing an even faster and more responsive user interface (UI) with timely alerts and active monitoring. Pubmatic believes in putting our clients first by delivering the highest quality solutions and innovating efficient infrastructures. To learn more about our recent projects, check out our engineering content. If you would like to join our team, check out our open positions.