

In terms of technological sophistication, the ad-tech industry has witnessed tremendous growth in the last few decades. With cutting-edge technology at their disposal, marketers generate an enormous amount of data. Consequently, companies like PubMatic must invest in applications that are highly scalable and extendable.
The PubMatic platform serves as the hub for proprietary applications that receive, process, and store tens of billions of ad requests in a day. Naturally, these applications need to be updated from time to time, and we recently revamped Audience Ingestion.
Audience Ingestion — What it is and the Challenges We Faced
At PubMatic, we use audience data to perform user segmentation for targeting digital users with relevant ads. Data providers feed data into the PubMatic servers. Our system handles the validation, processing, and storage of a colossal amount of PubMatic database requests every day.
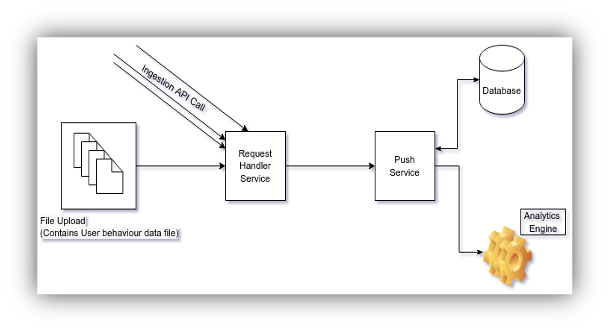
The current architecture could not practically shoulder changing market dynamics, limiting our ingestion potential. As issues such as non-containerized nature of the application failed to support a considerable increase in the number of data providers, we became conspicuous, and we faced a dilemma. We asked ourselves if we should redesign the current architecture of the application or rewrite the entire application code.
The Solution
The PubMatic engineers identified a range of issues; the most prominent of which was the communication between Request Handler Service and Push Service. The Request Handler component generates JSON for each user’s ingestion request, which is then received by the Push Service component and executed periodically.
To offset the effect of this tightly coupled interaction within the application, the team decided to rewrite the complete application. This was because the redesigning efforts on just these two components alone roughly equaled that of rewriting the code.
How We Performed The Ingestion Revamp
We employed the following best practices to ensure the timely delivery and performance of the Ingestion module revamp:
- Performed reverse engineering on the existing application to gain a better understanding of its functionality and code flow
- GO emerged as the language of choice for the Ingestion pipeline instead of the earlier C language
- To keep the pipeline from becoming too complicated, the team simplified obvious codes and removed redundant ones
- Avoided premature optimization of the code
- Followed microservice best practices throughout the revamping process, such as:
- Defining interfaces first and then implementing them
- Caching dirty/stale reads
- Ensuring invalidation of cache at regular intervals
- Using updated benchmarking test cases, among other
- Once our APIs were built, we made sure to undertake proper performance benchmarking.
To wrap it all up, the team decided to eliminate manual deployment for good. So, we equipped the updated application with Containerization, Push-button deployment, Test Automation, and Environmental Stability.
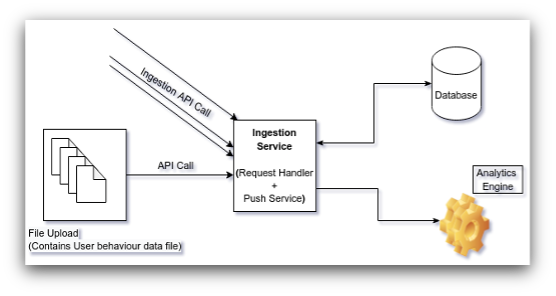
The Outcome — Enhanced Performance from Day One of the Roll-Out
The team decided to partially roll out the new code in one of our data centers to monitor its performance in a controlled environment. Within a short amount of time we observed substantial enhancement of performance in comparison with the legacy application.
Our new Ingestion application is up and running stably in our 8 data centers while serving request traffic of billions daily. Our revamp effort improved our scalability and extensibility potential and enabled us to weed out the operational inefficiencies of the system.
All in all, upon evaluation, we can proudly stand by our decision to rewrite the application code instead of redesigning the application components individually.
Co-authored by Shweta Oak, Priya Mahajan, and Amritanshu Shekhar