

In the digital advertising industry, fraud and domain spoofing are major concerns for both publishers and buyers. To combat this issue, the Interactive Advertising Bureau Tech Lab introduced the ads.txt initiative. This file format allows publishers to publicly list companies authorized to sell their digital inventory, making it easier for buyers to verify if the company they are buying from is, indeed, an authorized seller. PubMatic has taken this initiative to the next level by developing Crawler 2.0, a next generation ads.txt crawler. In this post, we will discuss the limitations of the existing system, the need for an event-driven architecture, and the design of Crawler 2.0.
Limitations of the Existing System
PubMatic’s first ads.txt crawler and filtering system was a great achievement, but the design of the system had some shortcomings, including high dependence on the database and a lack of resilience. The system relied heavily on the database, using an update + select process to retrieve domains for processing. This could result in database locks and decreased performance. Additionally, the system was not equipped with fail-safe mechanisms, and any errors that occurred during domain retrieval would result in the domain being skipped until the next crawl.
Why Event-Driven Architecture
To overcome these limitations, PubMatic decided to switch to an event-driven architecture. This design pattern is based on the idea of triggering events based on specific actions and allowing the system to respond in real-time. This pattern is especially useful in situations where there is a need to process large amounts of data quickly and efficiently.
Design of Crawler 2.0
Crawler 2.0 has four main components: Watcher, Distributor, Loader, and Parser and Saver.
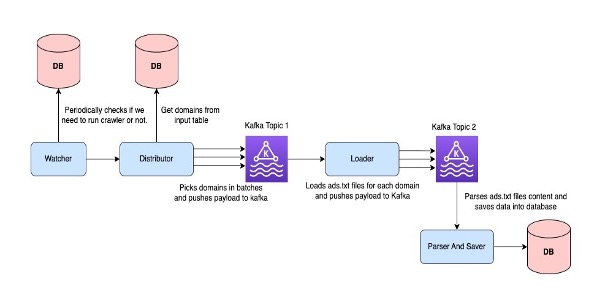
The Watcher regularly checks the crawler’s progress and asks the Distributor to crawl ads.txt files for the domains if necessary. The Distributor component is designed to be lightweight and fast, and it adds domain data to a Kafka topic. This allows each crawler to know the domains it needs to process, preventing row contention. The Loader component loads the ads.txt data and pushes its contents to another Kafka topic. The parsing and saving operations are decoupled so that they can be scaled independently. In the event of any failures during the addition of the batch to the Kafka topic, we implement retries every hour to ensure a robust system. To address the issue of large payloads in Kafka, we have created and implemented a solution that reduces the size of the payload by 90% improving the processing of ads.txt files for domains that are loaded in batches and to maintain the resilience of our system.
Scaling
The process of scaling Crawler 2.0 has become notably simpler, facilitating the growth of domains and apps on the PubMatic platform. This can be achieved by increasing the number of partitions in the Kafka topic and increasing the number of pods for the Loader and Parser.
Monitoring and Alerting
To ensure that the system is operational 24/7, PubMatic has put in place a monitoring and alert system that drives the successful crawling of all domains and the proper handling of any failures.
Crawler 2.0 is a next generation ads.txt crawler that addresses the limitations of the previous system and provides a real-time solution for publishers and buyers to combat domain spoofing. With its event-driven architecture, the system can process large amounts of data quickly and efficiently.